笔趣阁小说爬取工具针对笔趣阁网站开发,由论坛用户原创制作并分享,基于Python编写,能够帮助喜欢阅读小说的用户们将自己喜欢的文章下载到电脑上,让阅读进行得更加方便,软件免费实用,直接爬取网站下载小说资源,让用户轻松获取想看的小说,软件附源码。
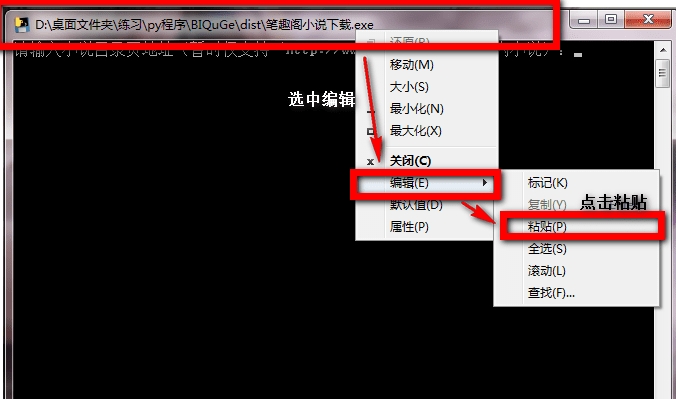
程序运行方法:解压,在本文件夹中找到并打开dist文件夹,有一个“笔趣阁小说下载.exe”,双击运行
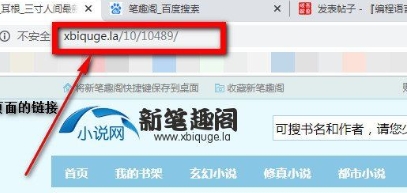
1、前往http://www.xbiquge.la/,找到要保存的小说,复制那个小说的目录页链接
2、按要求输入链接地址和小说名
3、爬取开始
(因为是单线程运行,爬取速度略慢大概1-2秒一章)
4、爬取结束后,会将所有章节内容整合成一个txt文件
import requests
import re
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
#定义全局变量,用于保存所有获取到的小说内容
story_all = []
#获取标题及章节链接地址
def main():
url = input(“请输入小说目录页地址(暂时仅支持‘http://www.xbiquge.la/’站内小说):“)
book_name = input(“请输入小说名称:“)
print(“-----爬取开始-----“)
#获取目录页的HTML文本
text = requests.get(url,header).content.decode('utf-8')
#获取每个章节的章节名
title = re.findall(r'
.*?
(.*?)',text,re.DOTALL)#获取每个章节的链接地址
loca = re.findall(r“
.*?='(.*?)' >“,text,re.DOTALL)
#因为title和loca的长度相同,所以以索引的方式遍历,方便取值
for i in range(len(title)):
content(title[i],f'http://www.xbiquge.la{loca[i]}')
#小说爬取完毕,开始保存
print(“@“*500)
with open(r'%s.txt'%book_name, 'w',encoding='utf-8')as file:
#遍历每一项,按顺序保存章节名和章节内容
for story in story_all:
file.write(story['title']+' ')
print(story['title'])
file.write(story['story'])
#解析章节内容并保存
def content(title,url):
#获取章节页的HTML文本
text = requests.get(url,header).content.decode('utf-8')
#因为之前写过直接爬取所有内容的,爬取出来的文本都带有不好处理
#所以就一句一句的获取了
story_content = re.findall(r' (.*?) #因为章节名中有“”空格,没办法作为文件名,所以把空格去掉 title = re.sub(' ','-',title) #有时候不知道为什么小说内容会爬取到一个空数组,所以这里添加了一个检测程序 #如果爬取到的为空,就重新爬取,直到获取到为止 if story_content==[]: content(title,url) return 0 story=““ #前面提到,因为我是一句一句爬取的,所以这里做一下拼接,顺便去空格 for story_contents in story_content: story = story+story_contents.strip()+'
' #将章节名称和章节内容保存为一个字典 this_story = { “title“:title, “story“:story } print(this_story['title']) #将字典添加到开头定义的全局变量中 story_all.append(this_story) if __name__ == “__main__“: main() 喜欢小编为您带来的笔趣阁小说爬取工具【附源码】吗?希望可以帮到您~更多软件下载尽在软件站。
 下载
下载
巅峰Q神QQ成长值领取工具 5.54MB / 小编简评:巅峰Q神(qq成长值一键领取)是一款市面是较的集QQ签到,
小编简评:巅峰Q神(qq成长值一键领取)是一款市面是较的集QQ签到,
 下载
下载
好易宝宝贝下载 3.08MB /
小编简评:好易宝宝贝下载可以轻松下载淘宝宝贝,导入淘宝助理上传
 下载
下载
广东人才培训网湛江分站-全通领航软件 394.42KB / 小编简评:广东人才培训网湛江分站,全通领航软件专注于网页操作简
小编简评:广东人才培训网湛江分站,全通领航软件专注于网页操作简
 下载
下载
Advanced 3.06MB /
小编简评:SMTP服务器软件,支持多种邮件客户端,并且可以保证邮件传
 下载
下载
SRWare 65.19MB /
小编简评:SRWare Iron浏览器号称是谷歌浏览器安全版,是一款在谷
 下载
下载
WebLight 18.31MB /
小编简评:软件可以检查网站的HTML错误、失效的连接和其它连接问
CopyRight © 2020-2025 www.zxian.cn All Right Reser 忠县软件园皖ICP备2023013640号-13 免责申明
声明: 本站所有手机app软件和文章来自互联网 如有异议 请与本站联系删除 本站为非赢利性网站 不接受任何赞助和广告网站地图

 淘宝客推广大师网络软件立即下载
淘宝客推广大师网络软件立即下载 红阳QQ群成员提取器网络软件立即下载
红阳QQ群成员提取器网络软件立即下载 骨头批量QQ空间好友动态秒评秒赞助手网络软件立即下载
骨头批量QQ空间好友动态秒评秒赞助手网络软件立即下载 聚安IT设备自动巡检系统网络软件立即下载
聚安IT设备自动巡检系统网络软件立即下载 神奇网页图片下载软件网络软件立即下载
神奇网页图片下载软件网络软件立即下载 天翼云盘直链平台网络软件立即下载
天翼云盘直链平台网络软件立即下载 RaiDrive网络软件立即下载
RaiDrive网络软件立即下载 海盗QQ附近人定位采集器网络软件立即下载
海盗QQ附近人定位采集器网络软件立即下载 有道云笔记网页剪报网络软件立即下载
有道云笔记网页剪报网络软件立即下载 脸猪优惠券推送系统网络软件立即下载
脸猪优惠券推送系统网络软件立即下载


















 搬砖铺路王手机版立即下载
搬砖铺路王手机版立即下载 小白数据恢复专家立即下载
小白数据恢复专家立即下载 卓创短讯立即下载
卓创短讯立即下载 宠物天国立即下载
宠物天国立即下载 首负模拟器花光50亿游戏立即下载
首负模拟器花光50亿游戏立即下载 七勇者与魔王之城立即下载
七勇者与魔王之城立即下载 飞跃摩托最新版立即下载
飞跃摩托最新版立即下载 健聊立即下载
健聊立即下载 喜马拉雅立即下载
喜马拉雅立即下载 单机双扣手机版立即下载
单机双扣手机版立即下载 超经典纸牌当空接龙手游合集,不容错过
超经典纸牌当空接龙手游合集,不容错过 驾驶飞机跨越星际,飞行类精品手游合集
驾驶飞机跨越星际,飞行类精品手游合集 嗡嗡轰鸣,机车摩托车竞速类手游合集
嗡嗡轰鸣,机车摩托车竞速类手游合集 谁能成为枪王?化身狙击手一击毙命
谁能成为枪王?化身狙击手一击毙命 精品王炸斗地主类手游合集,随时随地打牌
精品王炸斗地主类手游合集,随时随地打牌 足球FIFA类手游合集,踢出你的致胜一球
足球FIFA类手游合集,踢出你的致胜一球